When creating a Pod in Kubernetes, the scheduler selects a Node that the Pod can fit on based on the resource requests defined in its spec. However, a Pod’s resource limits may exceed the total capacity available on a Node and by default can consume all available resources. This is an issue because Nodes run many system-critical services to manage the OS and Kubernetes runtime, and unless resources are set aside for these services, Pods and system daemons compete for the Node’s resources and this can lead to resource starvation issues, with processes being killed unexpectedly.
The Kubelet exposes a feature called Node Allocatable that helps to reserve compute resources for system services (networkd, sshd, etc) and Pod runtime processes (kubelet, docker daemon, containerd). This protects the system from resource starvation caused by excessive utilisation from Kube Pods running on a given Node. Configuring this appropriately however can be a little tricky, and if done wrong may result in core processes being abruptly killed taking your Node offline.
Before jumping into the Kubelet configuration, let’s touch on control groups first.
Cgroups is a Linux kernel feature that limits, accounts for and isolates the resource usage (CPU, memory, disk I/O, etc) for a group of processes that run within it. The cgroups framework provides the following capabilities:
The Node Allocatable Resources proposal document provides some recommended cgroup configuration for Kubernetes nodes.
In particular:
There are a range of flags that can be configured on the Kubelet to manage resource reservation, the more crucial ones are covered below.
kubeReserved: Set CPU, memory & ephemeral storage reserved resources for the container runtime processes. This includes kubelet and the docker daemon itself.
systemReserved: Set CPU & Memory reserved resources for system processes, such as networkd, sshd, udev, timesyncd, etc.
kubeReservedCGroup: Absolute name for the kubeReserved cgroup. The node allocatable design proposal document recommends this be set to /podruntime.slice.
systemReservedCGroup: Absolute name for the systemReserved cgroup. Generally, this is /system.slice which all system processes are started under.kubeletCGroups: Absolute name for the cgroup that Kubelet should run within.
runtimeCGroups: Absolute name for the cgroup that the container runtimes should run within.
enforceNodeAllocatable: A comma-separated list of levels of node allocatable enforcement applied by the kubelet, set to pods by default (available options: pods, kube-reserved, system-reserved).
Only set the enforceNodeAllocatable flag if you have sufficiently profiled the resource utilisation of services within the kube runtime and system cgroups and set their reserved resource limits accordingly! If set and the system or kube runtime processes exceed their resource reservations, they may be killed or fail to start. By not enforcing these two limits, they still have reserved resources but are allowed to overflow to the node’s total available resources.
Kubelet by default will always create the root /kubepods cgroup, which all Kubernetes pods are started within. As the enforceNodeAllocatable flag defaults to pods, this also means that a resource limit is enforced for the /kubepods cgroup.
If the systemReserved & kubeReserved resource amounts are set, these are subtracted from the total resources available on a node and the remainder is defined as an enforced limit on the/kubepods cgroup. It is not required to explicitly set cgroups for kubeReserved and systemReserved, unless you want to have the ability to more finely control and limit resources for services running within them (or if you’ve configured enforceNodeAllocatable, which will cause Kubelet to error until these cgroups have been defined).
Following the Node Allocatable Resources design proposal, our additional Kubelet configuration now looks as follows (suggested limits will vary based on your node capacity and kube runtime / system process resource utilisation):
kubeReserved: cpu: 1000m memory: 1024Mi ephemeral-storage:
1024MikubeReservedCgroup: /podruntime.slicekubeletCgroups: /podruntime.sliceruntimeCgroups: /podruntime.slicesystemReserved: cpu: 1000m memory: 1024MisystemReservedCgroup: /system.slice
Before applying our new Kubelet configuration, we first need to make sure the desired cgroups have been created and are configured appropriately for the relevant services.
Kubelet does not create any other cgroups aside from /kubepods, so the systemReservedCGroup and kubeReservedCGroup must be created manually (if they don’t already exist) prior to starting the Kubelet Service, otherwise the Kubelet will end up in a crash loop. By default the /system.slice cgroup should exist and the kube runtime services run under that (unless explicitly configured otherwise). That leaves the /podruntime.slice to be created manually prior to loading the new Kubelet configuration.
If you are using kops to build and manage your Kubernetes Clusters, you can provide the following snippet within your Kops ClusterSpec as a FileAsset to create the cgroup prior to starting the container runtime and kube services:
fileAssets:- name: podruntime-slice path: /etc/systemd/system/podruntime.slice content: | [Unit] Description=Limited resources slice for Kubernetes services Documentation=man:systemd.special(7) DefaultDependencies=no Before=slices.target Requires=-.slice After=-.slice
Next, a drop-in is required for containerd and the Kubelet Service in order to ensure they use the newly created cgroup, and also to enable Kubelet to create the relevant cgroup paths for CPU & Memory accounting:
fileAssets:- name: kubelet-cgroup path: /etc/systemd/system/kubelet.service.d/10-cgroup.conf content: | [Service] CPUAccounting=true MemoryAccounting=true Slice=podruntime.slice- name: containerd-cgroup path: /etc/systemd/system/containerd.service.d/10-cgroup.conf content: | [Service] Slice=podruntime.slice
Note: From kops v1.12+, the CPUAccounting & MemoryAccounting are included in the Service by default and no longer need to be manually included as above. The Slice must still be provided however to ensure it starts under the desired cgroup.
Now that the required cgroups are created, you can apply your Kubelet configuration and restart the service for the changes to take effect!
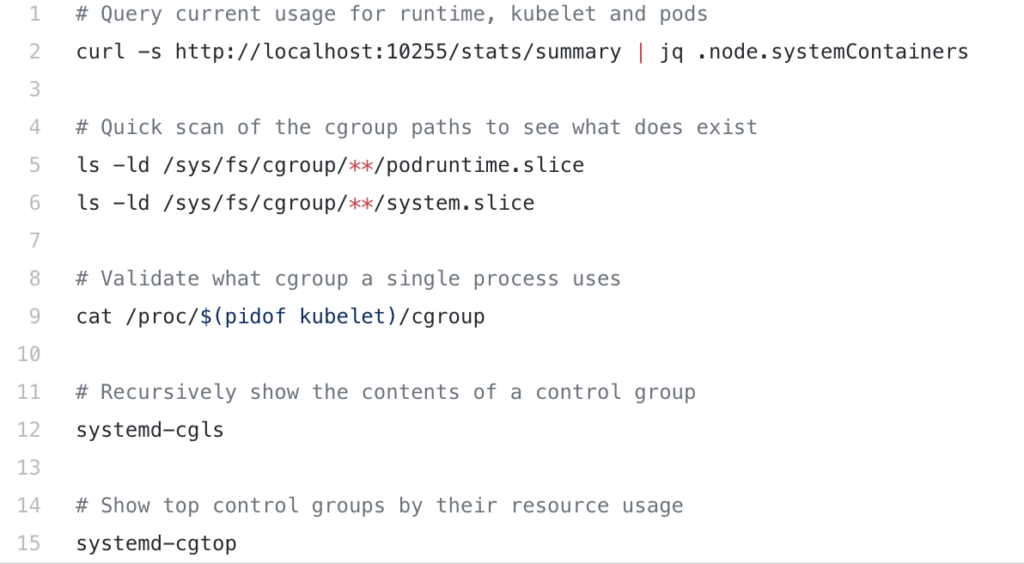
Included below are some helpful commands for debugging cgroups and resource utilization on nodes.