
A successful platform team delivers consistency across application development and deployment for the entire business. The goal of the platform engineer is to provide a platform that allows for this consistency without detracting from the development process itself. It’s often intertwined with DevOps — the process of enabling fast application delivery at a project level — but significant differences exist. The platform team is broader in scope and is responsible for ensuring consistency and reducing friction across the business.
Being a successful platform team starts with understanding what a successful team looks like. The goal of a platform team is to provide a simple developer experience that caters to the application lifecycle while encouraging high-quality outcomes for the developers. This is easier on paper than in practice, but teams can achieve this by engineering away complexity to remove friction for developers and their ability to ship applications into production. The goal is to make this process as frictionless as possible for the developers, allowing them to create and deploy high-quality, secure applications.
Introducing a platform engineering tool can simplify the process. A DevOps platform unifies management of all stages of an application’s lifecycle, enabling your organisation to build secure, high-quality applications faster. It can also help maintain consistency across your business.
A platform engineering team is a series of engineers who support and maintain the infrastructure needed for a cloud platform. It can be seen as an extension of DevOps but exists to facilitate a smooth experience for both development and operations. While a platform team is vital to a successful deployment strategy, creating a DevOps platform team requires significant funds, time, and other resources. Understanding the team’s success involves monitoring the operational efficiencies of the platform capabilities provided to the developers. If the overhead cost outweighs the efficiency brought to the development team, then the platform team must adjust its approach.
So how do you know if your DevOps implementation is successful? How do you know if your cloud platform is serving you well? And how do you know if your platform team is working effectively? This article will explore how monitoring metrics can help you determine the success of your platform engineering team.
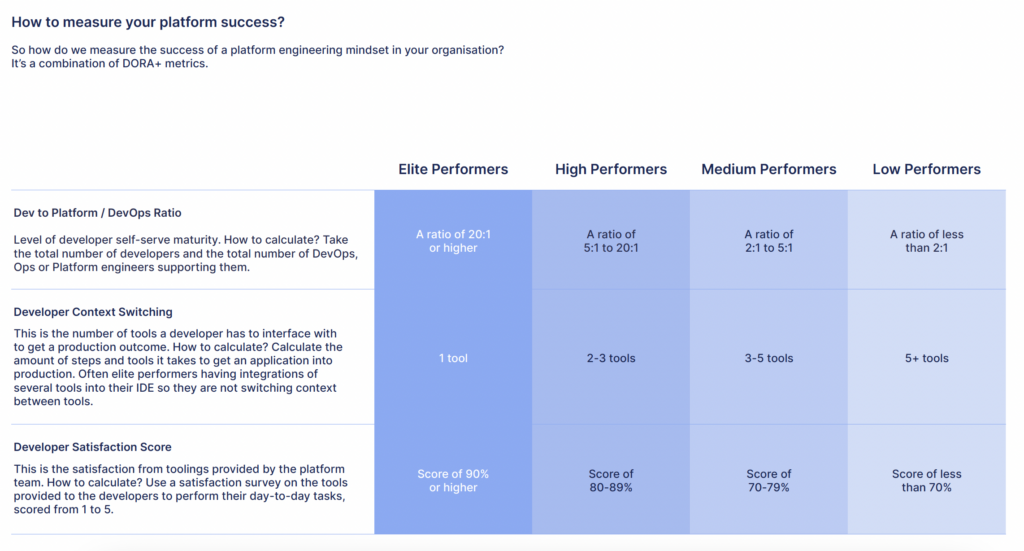
An accurate measure of a platform team’s performance can help improve its performance and consistency. DevOps and platform-related fields are often difficult to measure accurately, though some established metrics can help.
The DevOps Research and Assessment (DORA) team from Google has put together a series of measurements to help you understand the efficiency of your DevOps team. The four metrics used by DORA are:
These metrics can help you get an overall feel for the quality and speed of application delivery. However, they often fail to capture key business drivers that indicate operational efficiency. You should weigh application delivery against overall team size, cost of overall delivery, and cost of ownership of the engineering effort associated with the platform itself.
Additionally, to increase the success of this exercise, you must consider points not included in the DevOps metrics, including:
While DevOps metrics are good at showing team performance, they aren’t so good at tying those metrics to tangible business outcomes. To understand team performance from a business perspective, you must also factor in the team’s impact on the bottom line. This involves measuring and monitoring the cost of each step in the development lifecycle.
Additionally, when breaking down your costs, you must track all expenses related to delivery, maintenance, and support to fully understand the team’s operational efficiency. Ongoing support is easy to overlook, but it hugely affects overall costs. Your expense breakdown should separate business support costs from the costs associated with project delivery and factor in expenses related to ongoing support and maintenance of the technologies you’re using.
Maintenance is sometimes tricky to track, as it can include many unanticipated items. Things such as upgrading to new versions of different tools — including Kubernetes, which can be a very complex upgrade — and testing new releases should be included in maintenance expenses, as these activities can be both resource-intensive and time-intensive. By tracking maintenance costs independently, you can easily understand the success of your DevOps implementation and your platform team by determining how much time and money you’re investing into making your products work. Things you can factor into these maintenance and ownership costs include:

DevOps metrics may not be specifically tailored to platform teams. However, as they work hand-in-hand, many DevOps-related metrics are also good indicators of how your platform team works.
Both DevOps and platform teams focus on the speed and accuracy of application delivery, and any DevOps metrics measure that. And while no DevOps metric can comprehensively show the team’s performance in isolation, those outlined below relate to deployment speed and can illustrate your platform team’s performance.
Deployment frequency measures how fast a team delivers new code to production and how frequently an organisation delivers value to its customers. The higher the deployment frequency, the better the DevOps platform serves the application delivery teams.
A good deployment frequency is between once a day and once a week. A consistent increase in frequency indicates an increase in efficiency. Since a shorter time-to-market is a competitive advantage, high deployment frequency benefits an organisation.
You can improve this metric by automating tests in the continuous integration and continuous deployment (CI/CD) pipeline. Decoupling the development process will also improve this metric. For instance, the API management team shouldn’t delay a user interface improvement that doesn’t affect the back end.
Of the organizations that have implemented platform teams, 68 percent have seen an increase in development velocity. This drastically impacts deployment frequency and is a great way to measure how successfully your platform team performs.
Lead time for changes measures the average time between identifying and implementing a necessary code change. A fast lead time indicates that the platform team serves the developers well, as they can create and deploy changes quickly. For this to happen, the platform team must execute the correct architectural practices for fast code releases.
Measuring the time between the sanctioning of a change and when it’s available to users can inform management of how well your organisation addresses customer feedback and makes relevant improvements. It also indicates that the code can be patched quickly and reliably, greatly reducing security risks. You should always strive to achieve a shorter lead time for changes.
The next step is to add all individual lead times over one or two weeks and calculate the average. A good lead time to change is between one day and one week. You can improve this metric by minimising dependencies and maximising autonomy within the platform.
Change failure rate measures the percentage of code change that fails in production. This metric measures how much time the team spends resolving problems. If it’s too high, it means the team isn’t spending enough time building new features that add value. Ideally, this metric should be zero, but any value less than 15 percent is acceptable.
Change failure rate focuses on errors from changes in code already in production rather than errors caught during testing. You calculate the rate by dividing the number of failed deployments by the total number of deployments.
The change failure rate declines when the platform team makes environment provisioning quick and simple, allowing applications to move seamlessly through the environment lifecycle. This consistency ensures that testing is efficient and reliable, leading to smooth changes.
You can use ephemeral environments to reduce costs. This also brings the bonus of promoting a good architectural application process with robust testing.
Failures are bound to happen. That’s why organisations need a strong failure management mechanism. MTTR measures the average time it takes the team to rectify problems caused by changes in code. You calculate this metric by dividing the downtime by the total failed incidences.
You should strive to have MTTR be as low as possible because a high rate can breach service level agreements (SLAs). It can also signify a loss of revenue. The acceptability level of an MTTR is highly dependent on the industry and the existence of an SLA.
The platform team ensures the developers have the observability required to identify and rectify problems quickly and easily. Developers rely on the tools the platform team provides for visibility into the platform to facilitate diagnosis. When platform teams integrate observability solutions into the platform, developers can easily spot issues and determine where problems lie when a failure occurs.
Platform teams can improve this metric using failure-aware deployment methodologies, such as blue/green or canary. 60 percent of organisations note an improvement in system reliability when successfully using platform teams, which means fewer failures and more resources to tackle those that occur promptly.
Besides the core metrics, there a few others are worth mentioning.
Cycle time measures the time spent working on a specific item from the start to deployment. This shows how efficient the software development pipeline is.
A short cycle time helps a company reduce the time to market for new features. However, a short cycle time isn’t helpful if deployments break regularly — the proportion of successful deployments affects deployment stability.
Finally, availability measures the time an app runs without any problems. It determines whether a company is compliant with its SLA.
Measuring the success of a platform team’s performance requires several metrics. A single metric can help improve the platform functionality but can’t show the overall performance in isolation. Knowing the right metrics and interpreting these metrics enhances team performance.
Successful platform teams enable developers to securely and consistently deploy their applications, allowing for more frequent updates and a better customer experience of your apps.
Successful platform teams deliver consistency across application development and deployment, aiming to reduce friction and ensure high-quality outcomes for developers.
A platform engineering team supports and maintains the infrastructure for a cloud platform, aiming to facilitate a smooth experience for both development and operations.
Measuring the success of platform teams involves monitoring operational efficiencies, considering factors like deployment frequency, lead time for changes, change failure rate, and mean time to recovery.