
One of the main benefits of Kubernetes is its ability to dynamically change the environment to meet traffic needs. Containers, pods and even nodes can be created and removed as needed based on real-time traffic - which is referred to as autoscaling.
Autoscaling makes Kubernetes an extremely resilient and attractive container management environment.
But this capability comes with many challenges and complexities, with numerous parameters that have financial AND operational implications. Take this: Let's say you will scale your database when it reaches 50% CPU utilisation. That guarantees you're paying for a system that will never be more than half utilised. Is that a problem? Maybe.
It’s extremely common for different components to scale different rates. You might be able to bring up a new copy of your front-end application within two or three minutes, but, your backend database may take several minutes or even hours to replicate itself.
So given the above constraints maybe it's not such a bad idea to start replicating your database at 50% CPU utilisation.
We took this situation, and made it into a game called ‘Black Friday’. It’s no secret that Black Friday, the day after Thanksgiving in the US, is one of the busiest days for online retail merchants.
From 2019 to 2020, online Black Friday sales rose about 22% to $9 billion.
Source: Adobe via CNBC, 2020
Written by Appvia Solutions Architect Chris Nesbitt-Smith, the idea of the game is that you are in a large retailer whose Kubernetes environment needs to be tuned for scaling on Black Friday.
There are four tunable entities: Nodes, Frontend, Backend and Database. Each one can be changed individually to affect how they scale. Nodes and Database take the longest to scale, while Frontend and Backend take the least amount of time.
Since Nodes and Database scale more slowly, the temptation is to set their threshold to a low CPU value (say 20%). But that guarantees you will be wasting 80% capacity (and therefore money). On the other hand, you don’t want to scale too slowly since you will get failed requests which will affect your bottom line (as well as your SLAs).
So the goal is to save money by effectively utilising the current capacity, scale when you need additional capacity, and cause as few failed requests as possible.
For example, here the Frontend/Backend CPU scaling values were set to 90% and the Database to 30%. These are the results:
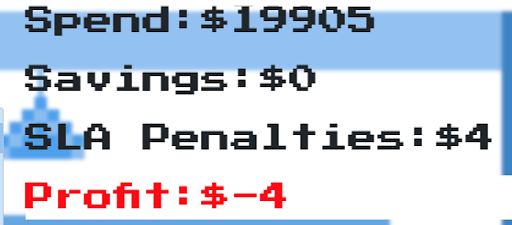
The result was that I didn’t save any money, but I did cost myself $4 in SLA penalties and this means I actually lost profits because of it.
Can you do better? We challenge you to try!