
Kubernetes is the de-facto standard for container orchestration. It has been since its introduction some six years ago.
But the one thing that is inescapable is Kubernetes complexity. It’s a difficult environment requiring a steep learning curve to seize its real potential.
But why does it have to be so dang complicated?
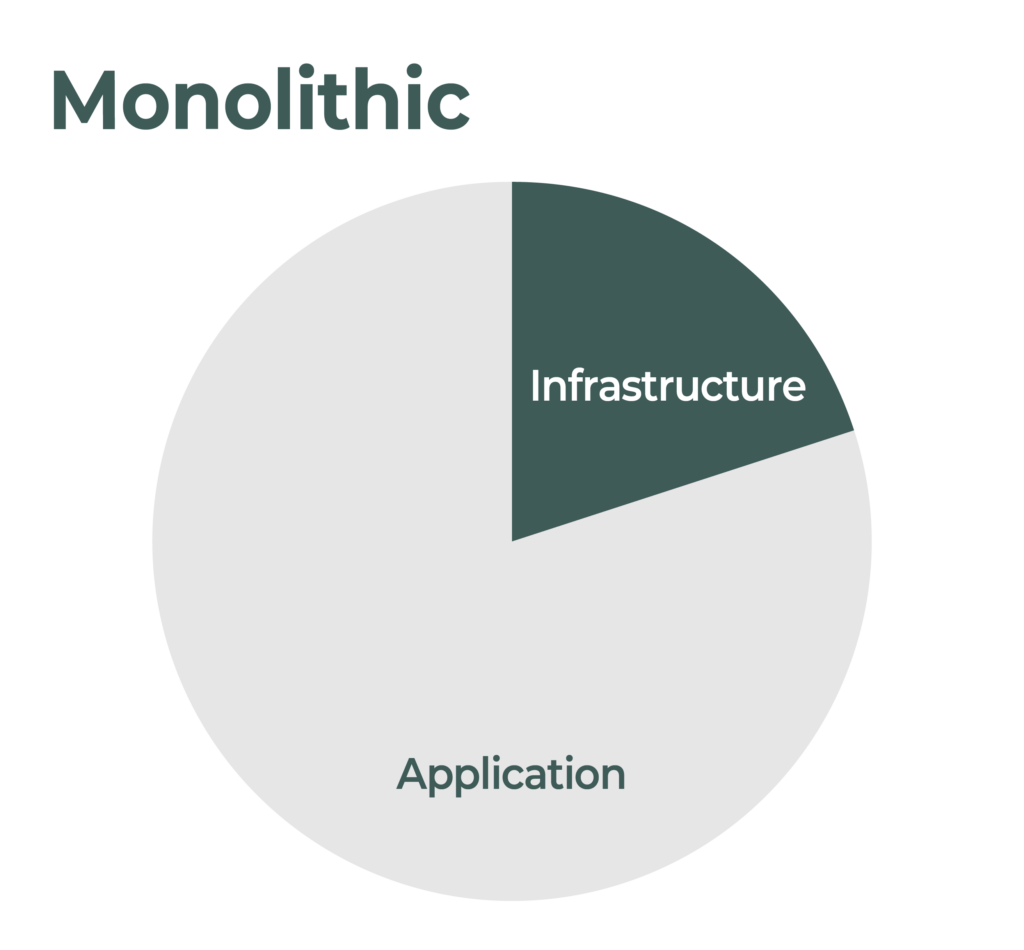
The reason is simple. Kubernetes defines a complex infrastructure so that applications can be simple. All of those things that an application typically has to take into consideration, like security, logging, redundancy and scaling, are all built into the Kubernetes fabric.
Put another way, the concept of infrastructure is divorced as much as possible from the applications and how they are constructed. Previously, a new application was essentially a custom solution. But an application in Kubernetes has no idea where it is running or how many copies are active. All of that is taken care of by configuration in Kubernetes itself. The application simply talks to well-defined APIs for the services needed.
So, once the Kubernetes infrastructure has been configured, the process of writing applications for it is relatively straightforward. All the application has to do is establish communications with other containers and process payload information. Gone are the days when you had to build new APIs for logging (for example) every time you built an application. In Kubernetes, you simply write to standard out and the data is added to the log.
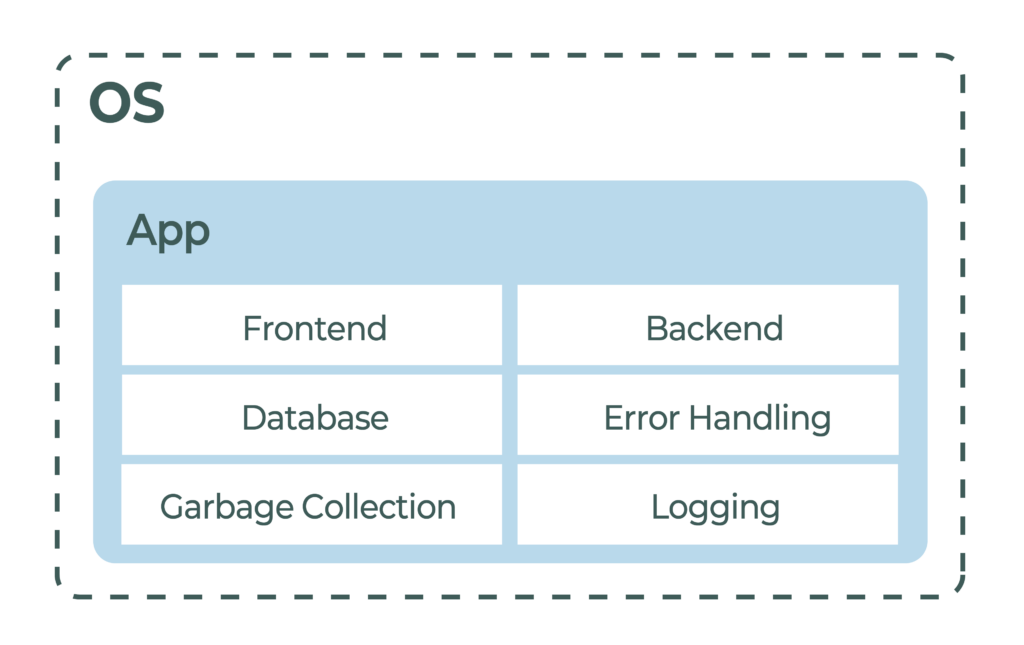
To illustrate this point, here is an abstracted depiction of an old monolithic application (below). Notice that things like logging and error handling are embedded in the application. The developer took all the responsibility for creating applications that were robust, scalable and observable. Long, tedious discussions would be held to design new APIs for things like logging and scalability, which had to be done because each application was a stand-alone entity requiring custom code.
Certainly, there was some opportunity to share libraries, but even then those libraries were custom creations requiring their own maintenance and support.
In contrast, here is an abstracted diagram (below) of the Kubernetes approach. Kubernetes creates a generalised environment in which there is automation available to handle things like deployment, scaling and management of applications.
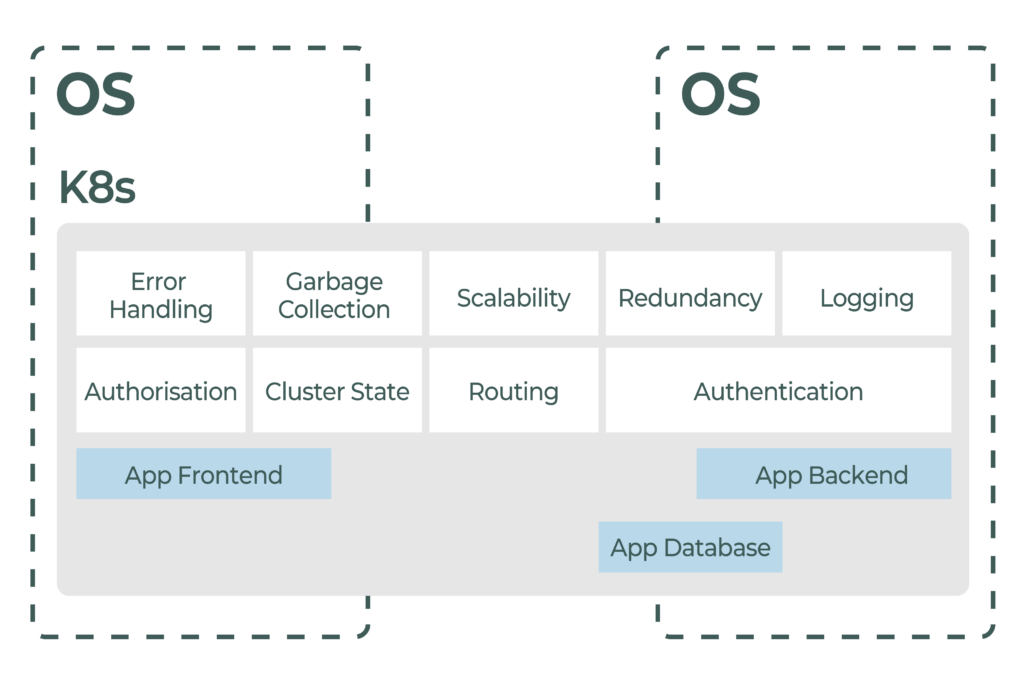
All common facilities needed by any application - like error handling, scalability and redundancy - are now located inside the Kubernetes ecosystem. Capabilities that were once part of the application code are now external, so the application code can be much smaller and simpler than before. The application can concentrate on processing payload data and doesn’t have to concern itself with ancillary things like scaling and redundancy.
How is this possible? It relies on a technology called containerization. It's a large subject and I won't go into it in any detail here but, in essence, it is a way to configure small pieces of code in discrete chunks that can be independently executed. Using containerization, a large monolithic application can be broken into much smaller independent pieces.
By coordinating the chunks together they create the equivalent functionality of the monolithic application we talked about before. This is tremendously beneficial because the components that make up the overall application can be separated into discrete pieces which are independently maintained and deployed. By doing this, you can iterate on releases much faster and with greater efficiency.
Kubernetes’ role in all this is to be the master choreographer to coordinate how all of these separate components interact.
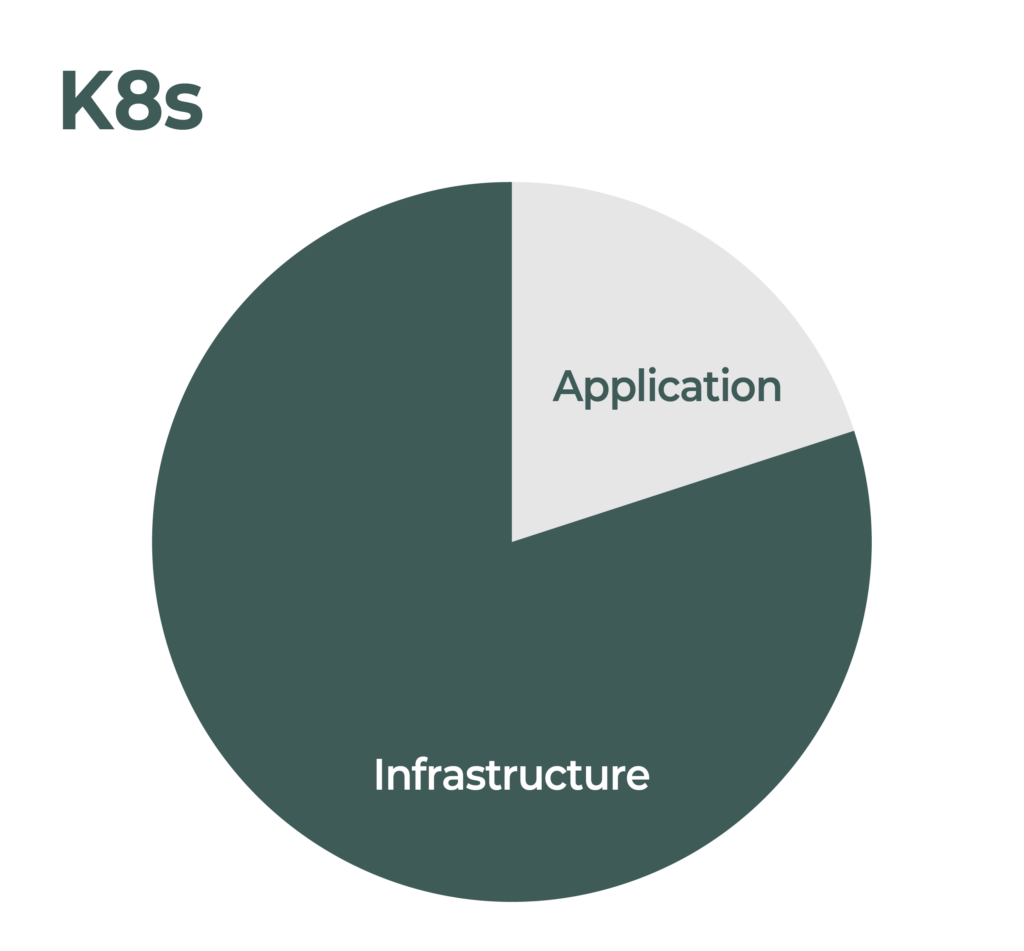
In order to do all this coordination among components, Kubernetes requires a huge amount of configuration. There are many many different parameters and settings to manage in order to make the environment suitable. Again, the environment is now where the complexity lives and not so much in the applications. In this new paradigm the burden has shifted from managing complexity inside the application to managing complexity in the supporting ecosystem.
For example, historically an application developer would have to concern themselves with how to scale their application - the system administrator would be only loosely involved in such a question. With containerization and kubernetes this predicament is reversed (see below). The application developer certainly needs to design the application to accommodate scalability, but the actual process of scalability has to be externally configured. The emphasis shifted from an application development challenge to an environment administration challenge.
This highly configurable infrastructure approach has caused a lot of fallout. Ironically, this pursuit of a simplified application environment has led to an explosion of configurable items in the Kubernetes ecosystem. In fact, it has become so excessively complex that it threatens to overshadow the whole effort of application deployment. In a recent survey, complexity was identified as the most challenging aspect of using containers in the Kubernetes environment.
To help illustrate what is meant by ‘complex’, here is a random excerpt from the Kubernetes documentation concerning a key/value storage object called a ConfigMap:
"When a ConfigMap currently consumed in a volume is updated, projected keys are eventually updated as well. The kubelet checks whether the mounted ConfigMap is fresh on every periodic sync. However, the kubelet uses its local cache for getting the current value of the ConfigMap. The type of the cache is configurable using the ConfigMapAndSecretChangeDetectionStrategy field in the KubeletConfiguration struct.
A ConfigMap can be either propagated by watch (default), ttl-based, or by redirecting all requests directly to the API server. As a result, the total delay from the moment when the ConfigMap is updated to the moment when new keys are projected to the Pod can be as long as the kubelet sync period + cache propagation delay, where the cache propagation delay depends on the chosen cache type (it equals to watch propagation delay, ttl of cache, or zero correspondingly)."
Got that? This isn’t to condemn, but rather to illustrate the dense logic that goes into the cluster setup process. In the pursuit of flexibility, the Kubernetes environment has become almost infinitely configurable. While this flexibility is praiseworthy, the confusing permutations and combinations have become unwieldy. It requires an encyclopedic knowledge to take advantage of the most basic capabilities.
If this is beginning to sound like an article to dissuade you from adopting Kubernetes, think again. In the same survey referenced above, one of their key findings was that:
Kubernetes use in production has increased to 83%, up from 78% last year.
Clearly, in spite of its complexity Kubernetes has much to offer and continues to dominate container orchestration.
But how can you manage that complexity? What do you do? What if your needs are modest and you just want to get your web applications running in a highly resilient environment?
When it comes to installing Kubernetes, we “get it”. We understand the pain of trying to simply stand up a working cluster. Our engineers have a long history of working with and maintaining enabling tools (like KOps) to mitigate complexity as much as possible.
We’ve taken that experience and created a product called Wayfinder, which takes the complexity out of creating and maintaining Kubernetes clusters.