
When you're navigating through an ocean of complex and unfamiliar terms and phrases, it can become difficult to keep up. Use this list as a go-to reference for understanding the most used Kubernetes terms to avoid being blocked and build on your foundation of knowledge. To get more insight into the background and functionality, check out our Guide to Kubernetes.
A group of nodes that run containerised applications. The cluster, and everything within it, is managed with Kubernetes.
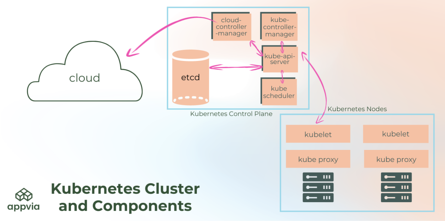
A cluster is made up of a master node and a set of worker nodes. While the control plane works to maintain the desired state of the cluster, the worker nodes actually run the applications and workloads.
Software technology that packages an application along with its runtime dependencies - most notably so that the application can run quickly and reliably across different environments. A common approach to containerisation is to run applications as microservices - this will allow you to achieve scalability and reliability.
Control loops that watch the state of your cluster and request changes where needed, trying to move the current state closer to the desired state. Kubernetes already comes with built-in controllers that run inside the kube-controller-manager (for example the Deployment and Job controllers).
Kubernetes allows you to run a resilient control plane, so that if any of the built-in controllers were to fail, another part of the control plane will take over the work. You can also write a new controller yourself, and run it either as a set of Pods or externally to Kubernetes, depending on what the controller does.
A component that makes sure a pod is running across a set of nodes in a cluster. A daemon set creates pods when a node is added, and garbage collects pods whenever a node is removed from a cluster.
A deployment is an object that manages a replicated application, making sure to automatically replace any instances that fail or become unresponsive.
Deployments help make sure that one (or more) instance of your application is available to serve user requests.
An open-source distributed key-value store which stores and manages the configuration data, state data and metadata for Kubernetes. etcd serves as the 'single truth' about the status of the system.
An API object that allows external access (aka outside the Kubernetes cluster) to your application. You need an ingress controller to read the Ingress resource information, process that data and get traffic into your Kubernetes cluster.
Wayfinder is a cloud-based platform that enables the automation of development environments and security standards for teams using Kubernetes.
Wayfinder is designed to make Kubernetes a commodity for organisations, allowing any team to be able to get Kubernetes simply and easily, without relying on specialist resources to provision it for you, set it up and give you access credentials.
A command line tool for communicating with a Kubernetes API server, used to create and manage Kubernetes objects.
Kubelets are an essential part of a Kubernetes cluster. Part of each node in the cluster, Kubelets make sure containers are actually running in a pod via the Kubernetes API server. They're also responsible for registering a node within a cluster and reporting on resource utilisation.
Embeds the core control loops shipped with Kubernetes. In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system.
Provides the frontend to the cluster's shared state, which is where all of the other components interact, and validates and configures data for API objects.
A network proxy that runs on each node in your cluster, maintaining network rules on nodes, which allows for network communication to your pods. It can run in one of these three modes: userspace, iptables or IPVS.
The default scheduler for Kubernetes, kube-scheduler is charge of scheduling pods onto nodes. It runs as part of the control plane, but is designed in a way that you can write and use your own scheduling component if it's preferred.
A tool that runs a single-node cluster inside a Virtual Machine on your computer. You can use Minikube to test out Kubernetes in a learning environment.
A virtual cluster where you can provision resources and provide scope for pods, services and deployments. They provide a scope for unique naming in order to divide cluster resources in an environment when there are several teams and/or projects.
A node is a worker machine in Kubernetes - a workload is run by putting containers into pods which run on nodes. A node can be either a virtual or physical machine, depending on the cluster.
You'll usually have several nodes on each cluster, and on each node you'll find the kubelet, kube-proxy and container runtime.
A way to make use of custom resources to create and manage applications and components.
The smallest object of the Kubernetes ecosystem, a Pod represents a group of one or more containers running together on your cluster.
An abstraction which defines a set of pods and makes sure that network traffic can be directed to the pods for the workload.
A name-string generated by Kubernetes to uniquely identify objects. Every object created in a Kubernetes cluster will have a particular UID.
Objects that define deployment rules for pods, around things like scheduling, scaling and upgrading. Kubernetes updates the workload with the current state of the applications, based on the rules that have been set.
At this point, you should have a good idea of the basic concepts and terms surrounding Kubernetes - but it doesn’t end here. Read through our Guide to Kubernetes for a more holistic view of Kubernetes usability and to try your hand at building a Kubernetes application with an example open source project the team at Appvia built to help walk you through.